To support the research projects in the Kraus Lab, we have developed and/or applied a wide variety of genomic tools, including novel computational pipelines designed to integrate, analyze, and visualize data from a wide variety of genomic (and proteomic) platforms. These include groHMM, a hidden Markov model-based algorithm for predicting primary transcription units based on GRO-seq data. We have used groHMM, which we deposited as an R-based package in Bioconductor for the community to use freely, to annotate thousands of previously unannotated noncoding RNA transcripts of unknown function. Furthermore, we have used genomic assays to examine the molecular mechanisms that drive signal-regulated transcriptional responses. These studies have characterized: (1) the robust and rapid changes that occur across the genome in response to estrogen and TNFα and (2) the expression of thousands of previously unannotated noncoding RNA transcripts, significantly altering our view of signal-regulated transcriptional responses.
We have recently developed TFSEE, a computational pipeline that integrates data from GRO-seq, RNA-seq, histone modification ChIP-seq, and motif searches, allowing for the simultaneous identification of putative subtype-specific enhancers and their cognate transcription factors. In addition to generating useful tools, our studies have helped to elucidate new facets of the genome and transcriptome.
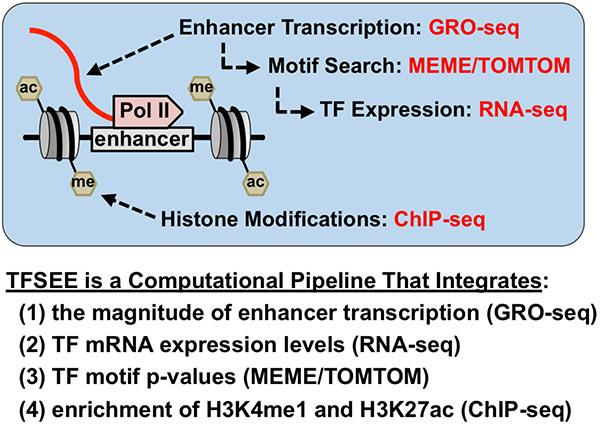 Total Score of Enhancer Elements (TFSEE) Simultaneously Identifies Putative Subtype-Specific Enhancers and their Cognate TFs
Total Score of Enhancer Elements (TFSEE) Simultaneously Identifies Putative Subtype-Specific Enhancers and their Cognate TFs Selected Publications
- Koul S, Kwon M, Tapadar P, Dai Y, Song W, Dasovich M, Nandu T, Huang D, Camacho CV, Kraus WL. Mapping the Subtype-Specific PARP1 ADP-ribosylated Proteome in Breast Cancer Cells. Mol Cancer Res. 2026 May 28. doi: 10.1158/1541-7786.MCR-25-1068. PMID: 42206981.
- Tripathy S, Nagari A, Chiu SP, Nandu T, Camacho CV, Mahendroo M, Kraus WL. Relaxin Modulates the Genomic Actions and Biological Effects of Estrogen in the Myometrium. Endocrinology. 2024 Sep 26;165(11):bqae123. doi: 10.1210/endocr/bqae123. PMID: 39283953.
- Owen DM, Kwon M, Huang X, Nagari A, Nandu T, Kraus WL. Genome-wide identification of transcriptional enhancers during human placental development and association with function, differentiation, and disease. Biol Reprod. 2023 Dec 11;109(6):965-981. doi: 10.1093/biolre/ioad119. PMID: 37694817.
- Huang D, Camacho CV, Martire S, Nagari A, Setlem R, Gong X, Edwards AD, Chiu SP, Banaszynski LA, Kraus WL. Oncohistone Mutations Occur at Functional Sites of Regulatory ADP-Ribosylation. Cancer Res. 2022 Jul 5;82(13):2361-2377. doi: 10.1158/0008-5472.CAN-22-0742. PMID: 35472077.
- Challa S, Khulpateea BR, Nandu T, Camacho CV, Ryu KW, Chen H, Peng Y, Lea JS, Kraus WL. Ribosome ADP-ribosylation inhibits translation and maintains proteostasis in cancers. Cell. 2021 Aug 19;184(17):4531-4546.e26. doi: 10.1016/j.cell.2021.07.005. Epub 2021 Jul 26. PMID: 34314702.
- Gupte R, Nandu T, Kraus WL. Nuclear ADP-ribosylation drives IFNγ-dependent STAT1α enhancer formation in macrophages. Nat Commun. 2021 Jun 24;12(1):3931. doi: 10.1038/s41467-021-24225-2. PMID: 34168143.
- Palavalli Parsons LH, Challa S, Gibson BA, Nandu T, Stokes MS, Huang D, Lea JS, Kraus WL. Identification of PARP-7 substrates reveals a role for MARylation in microtubule control in ovarian cancer cells. Elife. 2021 Jan 21;10:e60481. doi: 10.7554/eLife.60481. PMID: 33475085.
- Huang D, Camacho CV, Setlem R, Ryu KW, Parameswaran B, Gupta RK, Kraus WL. Functional Interplay between Histone H2B ADP-Ribosylation and Phosphorylation Controls Adipogenesis. Mol Cell. 2020 Sep 17;79(6):934-949.e14. doi: 10.1016/j.molcel.2020.08.002. Epub 2020 Aug 20. PMID: 32822587.
- Ryu KW, Nandu T, Kim J, Challa S, DeBerardinis RJ, Kraus WL. Metabolic regulation of transcription through compartmentalized NAD+ biosynthesis. Science. 2018 May 11;360(6389):eaan5780. doi: 10.1126/science.aan5780. PMID: 29748257.
- Franco HL, Nagari A, Malladi VS, Li W, Xi Y, Richardson D, Allton KL, Tanaka K, Li J, Murakami S, Keyomarsi K, Bedford MT, Shi X, Li W, Barton MC, Dent SYR, Kraus WL. Enhancer transcription reveals subtype-specific gene expression programs controlling breast cancer pathogenesis. Genome Res. 2018 Feb;28(2):159-170. doi: 10.1101/gr.226019.117. Epub 2017 Dec 22. PMID: 29273624.
- Nagari A, Murakami S, Malladi VS, Kraus WL. Computational approaches for mining GRO-Seq data to identify and characterize active enhancers. Methods Mol Biol. 2017;1468:121-38. doi: 10.1007/978-1-4939-4035-6_10. PMID: 27662874.
- Danko CG, Hyland SL, Core LJ, Martins AL, Waters CT, Lee HW, Cheung VG, Kraus WL, Lis JT, Siepel A. Identification of active transcriptional regulatory elements from GRO-seq data. Nat Methods. 2015 May;12(5):433-8. doi: 10.1038/nmeth.3329. Epub 2015 Mar 23. PMID: 25799441.
- Chae M, Danko CG, Kraus WL. groHMM: a computational tool for identifying unannotated and cell type-specific transcription units from global run-on sequencing data. BMC Bioinformatics. 2015 Jul 16;16:222. doi: 10.1186/s12859-015-0656-3. PMID: 26173492.
- Danko CG, Chae M, Martins A, Kraus WL. groHMM: GRO-seq Analysis Pipeline. R package version 1.0.0. Bioconductor. (Software) www.bioconductor.org/packages/release/bioc/html/groHMM.html